Building superior
product experiences
that make a difference



What
We Do
Technology innovation
is our greatest asset
We are technologists, creatives, and strategists that build great product experiences. We believe the world is a better place when products are designed and built the right way, are enjoyable to use and feel snappy. Our team of experts can deliver exactly the products you're looking for efficiently.
With Labs, we are constantly innovating with the latest technologies and applying our learnings to our clients. Today we specialize in purpose-driven progressive web apps, mobile apps, custom Headless CMS systems, and Ecommerce experiences.
Labs
Labs are our playground to create and experiment with products in-house before launching them to the public. Some of these experiments have turned into startups with enough success to lead to an acquisition. Take a look at what the minds at Fleet Studio are cooking up!
Product Dev
Identifying and solving business challenges can be a drawn-out and labor-intensive process. Luckily, helping you overcome your hurdles is in our wheelhouse. Bring us a challenge, and we will shoot back with a custom strategy and an implementation solution.
Digital Strategy
We are digital natives who know that using technology to amplify your products, ideas, and services is the key to success. Whether you want to move your business towards a digital-first product experience or want to optimize your performance, we will listen to your needs and customize a strategy that will push you ahead of the competition.
Design
If design is the first thing people notice, why should it be an afterthought? When it comes to the creative side of our projects, we don't believe in cutting corners. Our partnerships with excellent agencies mean we can hand the design work over to the experts, getting you the best possible product.
Why
Fleet Studio?
Technology innovation
is our greatest asset
Since 2008, we have worked with over 100+ brands including Puma, Diageo, Kimberly Clark, and more. Our flexibility and dependability enable us to successfully launch product experiences across consumer, fintech, edutech, adtech, martech, healthcare/ life science and automotive industries.































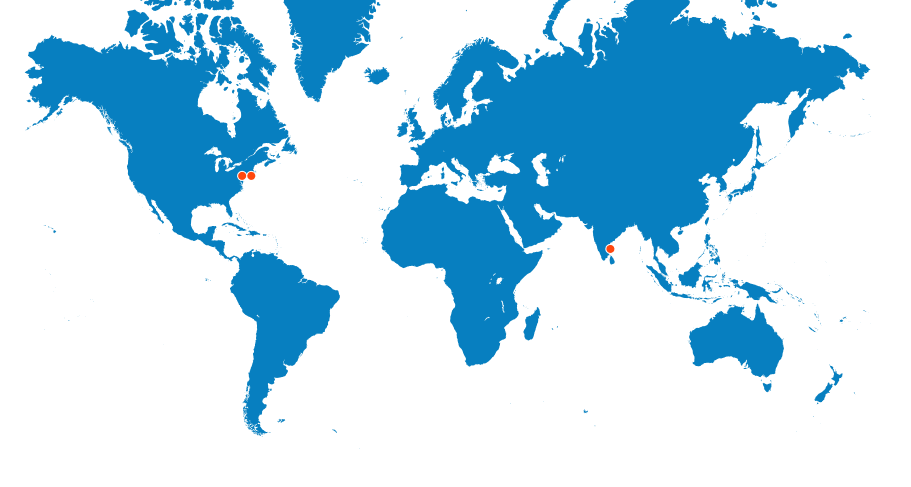
Global Teams Serving Global Clients
Our global presence spans across the bustling streets of New York City, the academic hub of Princeton NJ, and the vibrant city of Chennai, India. As a dynamic global company, we have the unique opportunity to collaborate with the biggest multinational corporations, the most influential marketing agencies, and the most promising startups on the planet. Join us on this exciting journey as we work towards driving innovation and progress on a global scale.